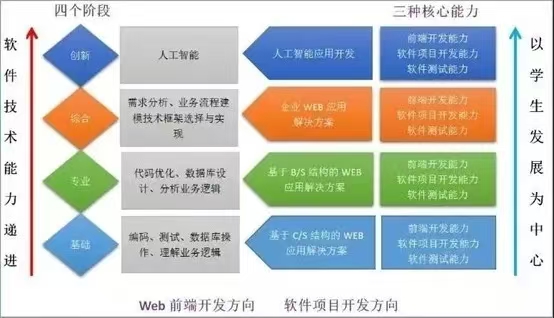
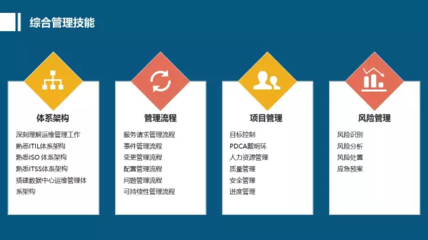
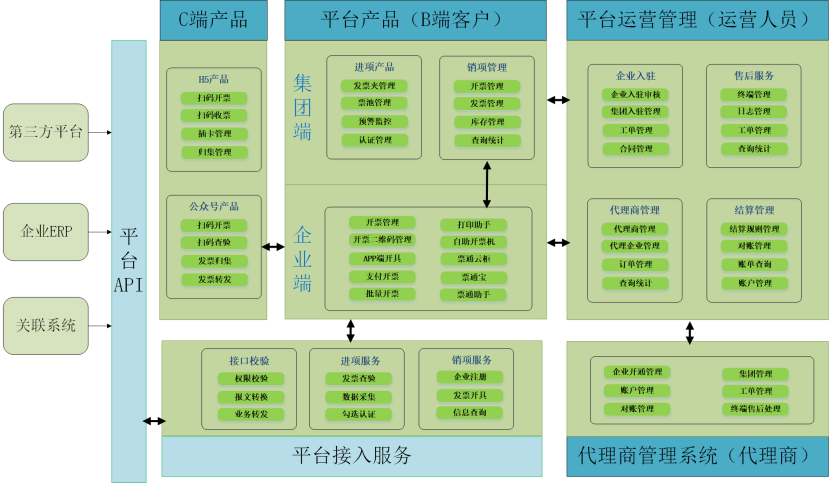
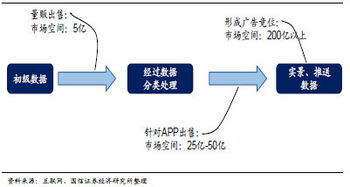
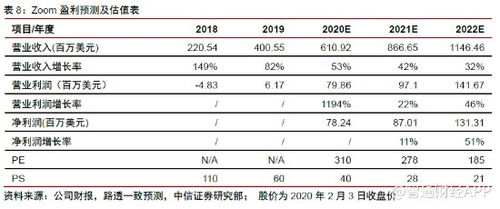
開源軟件通識基礎課程的第三周,聚焦于開源生態系統中的核心組成部分——應用軟件服務。本周的學習內容從理論到實踐,系統性地闡述了開源應用軟件服務的概念、類型、部署方式、社區協作模式以及其在現代技術棧中的關鍵作用。以下是對本周知識點的萬字,旨在幫助學習者構建一個清晰、全面的知識框架。
一、開源應用軟件服務的定義與核心價值
開源應用軟件服務,指的是基于開源許可證發布,旨在解決特定業務或技術問題的軟件應用程序。與底層系統軟件或開發工具不同,應用軟件直接面向最終用戶或特定業務場景,提供可立即使用的功能。其核心價值在于:
- 可訪問性與低成本:源代碼公開,允許任何人免費使用、學習和修改,極大降低了獲取和試錯成本。
- 透明與可信:代碼可見性確保了運作機制的透明,有助于建立信任,特別是在處理敏感數據時。
- 靈活性與可定制性:用戶可以根據自身需求,自由地修改、擴展或集成軟件,避免被供應商鎖定。
- 社區驅動與快速創新:全球開發者社區的共同維護,使得問題修復、功能更新和安全補丁的發布速度往往快于閉源軟件。
二、主要分類與代表性項目
開源應用軟件服務覆蓋了幾乎所有計算領域,主要可分為以下幾大類:
- 辦公與協作套件:
- 代表項目:LibreOffice, OnlyOffice。這些項目提供了媲美商業辦公軟件的文字處理、電子表格、演示文稿等功能,是個人和企業替代Microsoft Office或Google Workspace的重要選擇。
- 關鍵知識點:支持開放文檔格式(如ODF),確保數據的長期可訪問性和互操作性。
- 內容管理與發布系統:
- 代表項目:WordPress, Drupal, Joomla。它們構成了全球網站的基礎,允許用戶無需深厚編程知識即可創建和管理網站、博客、論壇及電子商務平臺。
- 關鍵知識點:基于插件和主題的擴展架構,擁有極其龐大的生態系統。
- 企業資源規劃與客戶關系管理:
- 代表項目:Odoo, ERPNext, SuiteCRM。為中小企業提供一體化的業務管理解決方案,涵蓋銷售、庫存、財務、人力資源等。
- 關鍵知識點:模塊化設計,允許企業按需啟用功能;社區版與商業支持版并行的商業模式。
- 媒體管理與流媒體服務:
- 代表項目:Jellyfin, Plex Media Server (核心組件開源), Nextcloud (包含媒體管理功能)。用于搭建個人或家庭的音樂、視頻、照片庫和流媒體服務器。
- 關鍵知識點:注重隱私和數據所有權,將媒體控制權從商業云服務商交還給用戶。
- 通信與協作平臺:
- 代表項目:Mattermost, Rocket.Chat, Matrix (協議及客戶端如Element)。作為Slack、Microsoft Teams的開源替代品,提供團隊聊天、音視頻會議、文件共享等功能,支持自托管。
- 關鍵知識點:對數據主權和安全有高要求的企業和組織的首選;支持與現有系統的集成。
- 開發與運維工具:
- 代表項目:GitLab, Jenkins, Gitea。雖然更偏向工具鏈,但它們以應用服務的形式提供,涵蓋了代碼托管、CI/CD、項目管理等完整的DevOps生命周期。
- 關鍵知識點:是開源理念在軟件開發實踐中的完美體現,自身開源的同時又服務于開源及閉源項目的開發。
三、部署與運維模式
開源應用軟件服務的獲取和使用方式多樣:
- 自托管:用戶在自己的服務器或云基礎設施上安裝和運行軟件。這提供了最高的控制權和數據所有權,但需要相應的技術能力進行安裝、配置、更新和維護。
- 云托管/服務化:由第三方提供商(如AWS Marketplace, DigitalOcean Droplets, 或項目官方云服務)提供托管服務。用戶以訂閱方式使用,無需管理底層基礎設施,降低了使用門檻。
- 桌面安裝:對于客戶端應用(如LibreOffice),直接安裝在個人電腦操作系統上使用。
- 容器化部署:以Docker容器或Kubernetes Helm Chart形式分發,成為現代云原生部署的事實標準,極大地簡化了環境依賴和部署復雜性。
四、社區參與與貢獻途徑
成功開源應用項目的背后,是一個活躍、健康的社區。參與方式包括:
- 用戶:使用軟件、提交Bug報告、在論壇回答問題、撰寫使用教程。
- 譯者:參與軟件界面和文檔的本地化翻譯工作。
- 測試者:測試預覽版或發布候選版,幫助發現潛在問題。
- 開發者:貢獻代碼、修復Bug、開發新功能或插件。
- 文檔貢獻者:改進和編寫用戶文檔、API文檔。
- 布道師:通過博客、演講、社交媒體宣傳項目。
五、挑戰與最佳實踐
- 挑戰:
- 選擇困難:同領域存在多個優秀項目,需根據技術棧、社區活躍度、文檔質量進行綜合評估。
- 運維負擔:自托管意味著承擔7x24小時可用性、安全更新、數據備份等責任。
- 長期可持續性:需關注項目的社區健康狀況、核心團隊的穩定性及資金模式,避免項目中止風險。
- 最佳實踐:
- 明確需求:清晰定義業務需求,避免被技術“炫技”所迷惑。
- 評估社區與生態:優先選擇有活躍社區、定期更新、擁有良好文檔和豐富插件/擴展的項目。
- 從小處著手:先進行概念驗證或在小范圍內部署試用。
- 制定運維計劃:規劃好部署、監控、備份、升級的流程。
- 考慮商業支持:對于關鍵業務應用,評估是否需要購買商業支持服務以獲得保障。
六、與展望
第三周的學習揭示了開源應用軟件服務作為數字化世界的基石,其廣度和深度正在不斷拓展。它們不僅為個人和小微企業提供了強大的免費工具,也為大型組織提供了避免供應商鎖定、實現技術自主的可行路徑。隨著云計算、容器化和人工智能的普及,開源應用服務正變得更加易用、智能和集成化。
掌握開源應用軟件服務的評估、部署和參與方法,已成為現代IT從業者、開發者乃至終端用戶的一項基本素養。開源應用將繼續驅動創新,在隱私保護、數據主權、數字包容性等方面發揮不可替代的作用。學習者應積極動手實踐,參與到感興趣的社區中,從使用者逐步轉變為貢獻者,親身感受開源協作的力量。